
Validation split
Before going further on the metrics used to evaluate the quality of a model, we need to introduce the notion of training and validation set.
To avoid any bias, we need to create two separate and independent sets of images. Indeed, you don't want to evaluate the performance of a model on the same set of images it has been trained on. Hence, we distinguish between training and validation sets. By default, when you do not specify any information, all the images that you add to a project are added to the training set. To create or change the validation set, you need to click on Perform a validation split on the navigation bar in the Galleries section.
If there isn't any bias in your set of images, you can do a random validation split directly from the home page of your project (see the Project Home Page section of the Managing projects & views page for how to access the home page of your project).
When clicking on Perform a validation split, you will see the following form:
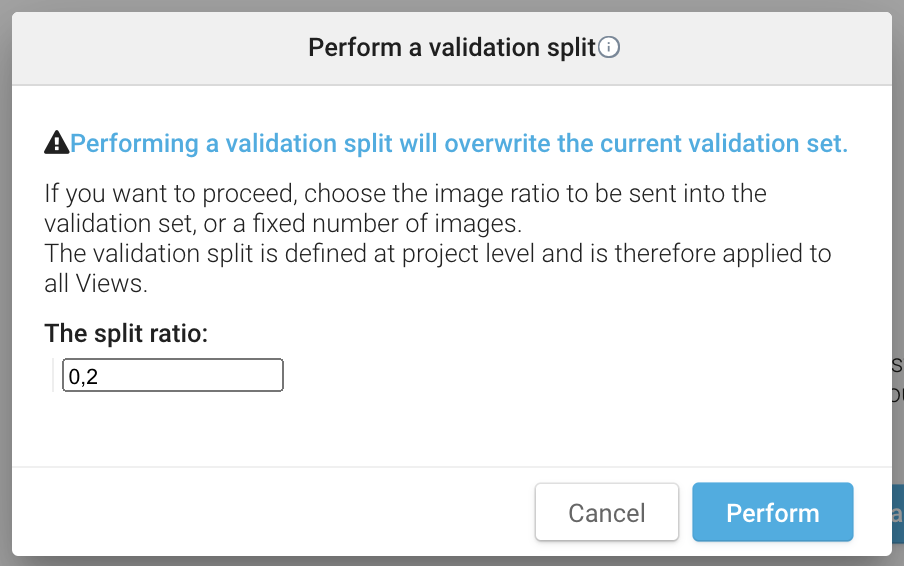
By entering an integer strictly greater than 1, you get a random validation split that makes sure to send the corresponding number of images in your validation set.
By entering a float between 0 and 1, you get a random validation split that makes sure to send the corresponding proportion of images in your validation set.
The same validation set applies to all your views.
After changing your validation set, it is no longer possible to compare two models.
Good to know: when you create a project from a text (JSON) file, you can directly specify to which set (training or validation) each image belongs. See the reference below:
Import/Export via studio UIWas this helpful?